直言直行 - ちょくげんちょっこう -
完成
© CC BY 4+
957
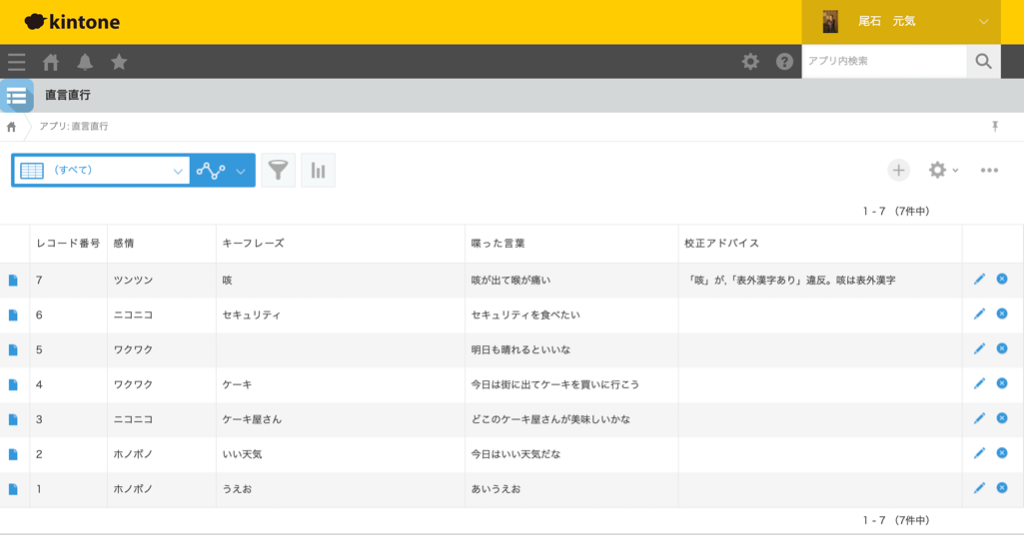
在宅勤務が増え、ほとんど業務はリモート会議になり、いざ喋ると日本語おかしいし、相手がうまく聞き取れてないことがあるのが悲しい。チャットとか文字でフォローするのめんどいし、なんとかしたい。
https://docs.google.com/presentation/d/1T55pwFisSi3aq4dhFfwKHi4eIfCC_hmEqN4dLfEnq_M/edit?usp=sharing
-
 ヤフー賞 by ヤフー株式会社ヒーローズ・リーグ 2022
ヤフー賞 by ヤフー株式会社ヒーローズ・リーグ 2022




- 動画
-
- 開発素材
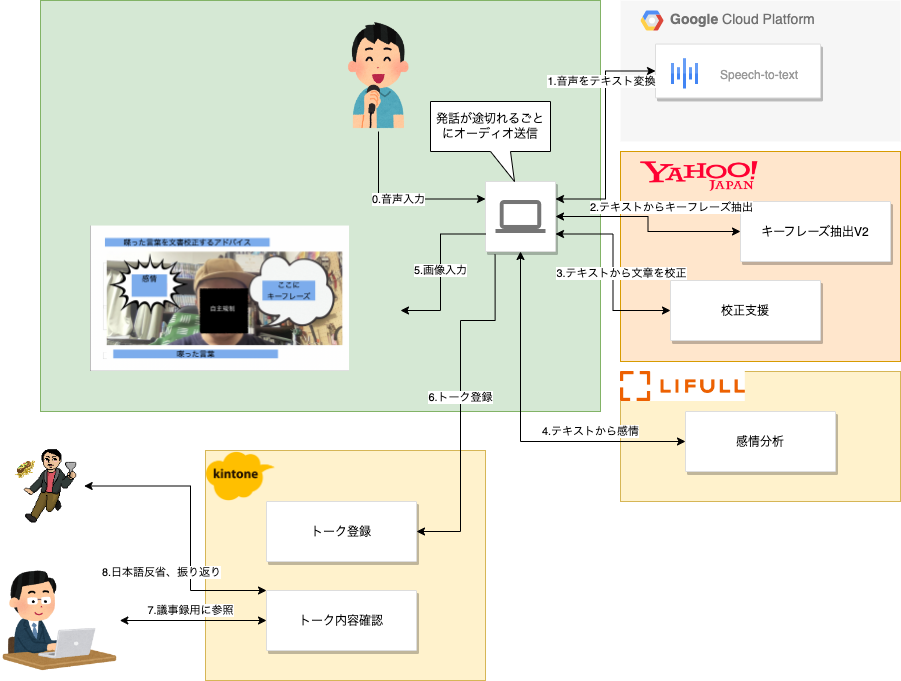
- システム構成
-
- ストーリー
-
- メンバー
-
-

- おいし もとき @motokioishi
-
-
- 関連イベント
-
-
 ヒーローズ・リーグ 20222022-09-05 開催
ヒーローズ・リーグ 20222022-09-05 開催
-
 #ヒーローズリーグ 2022 【決勝進出権有】 オンライン・ハッカソン2022-10-22 開催
#ヒーローズリーグ 2022 【決勝進出権有】 オンライン・ハッカソン2022-10-22 開催
-
- 関連リンク
-

-
- 同じニオイがする作品
-
-
 ソーシャルストリーミングリモコン
ソーシャルストリーミングリモコン
-
 3年日記電子版 by三日坊主チーム
3年日記電子版 by三日坊主チーム
-
 無能プラットフォーム by Team.fuckin-specs
無能プラットフォーム by Team.fuckin-specs
-
 BarSota
BarSota
-
Proto lovers ♥










音声、言語、画像と複数の入出力を組み合わせ、それらを処理する API をうまく活用した作品であり、時代の要請にもマッチしています。話し手への話した内容へのフィードバックと、聞き手への情報の補強という重要な機能に、校正支援とキーフレーズ抽出の API をご利用いただきました。提供する側の私たちも想像していなかった利用法であり、未来を期待させる作品だと思います。